深入解析 Use Memory 核心功能的处理流程。
在 Opal 的流程中,每个生成节点默认只会获取上一个节点的结果,相当于每个生成节点都是独立处理的。这就意味着单个生成节点不具备理解更多上文的能力,只能根据上一个节点的结果进行处理。在复杂的流程中,生成节点可能会忘记之前做了什么,导致最后生成的结果达不到预期的效果。
Use Memory 功能
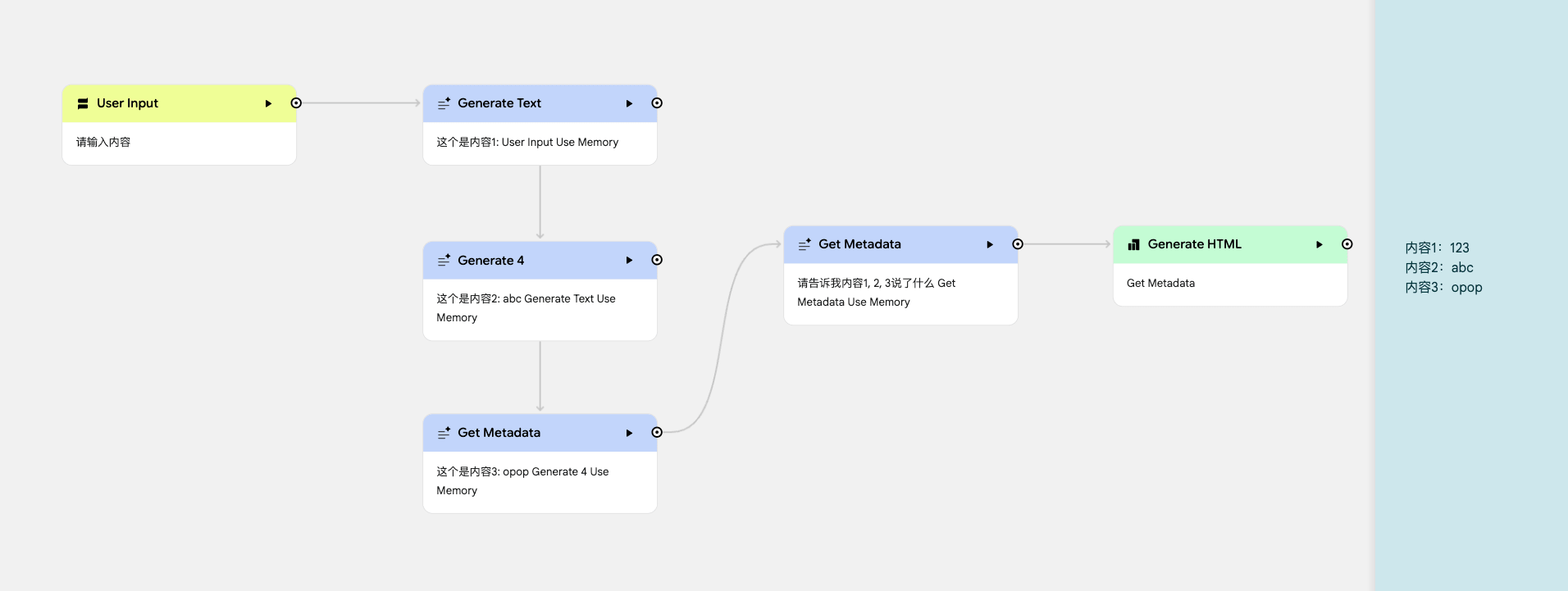
在生成节点中,使用 Use Memory 可以使用持久数据储存,在多个节点调用的时候记住数据。
使用标签,还是直接输入 Use Memory 关键词,系统底层触发的逻辑是一样的,结果也是一样的,没有区别。
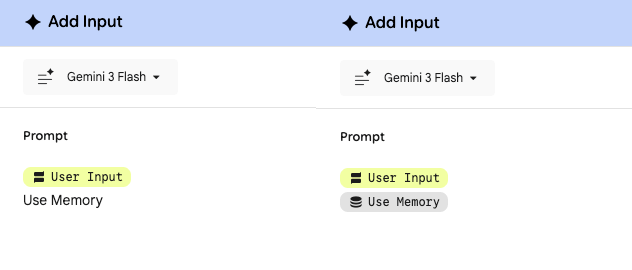
发送请求的时候,不管使用哪种方式添加的,参数里面也只是使用了 Use Memory 关键词。

处理流程
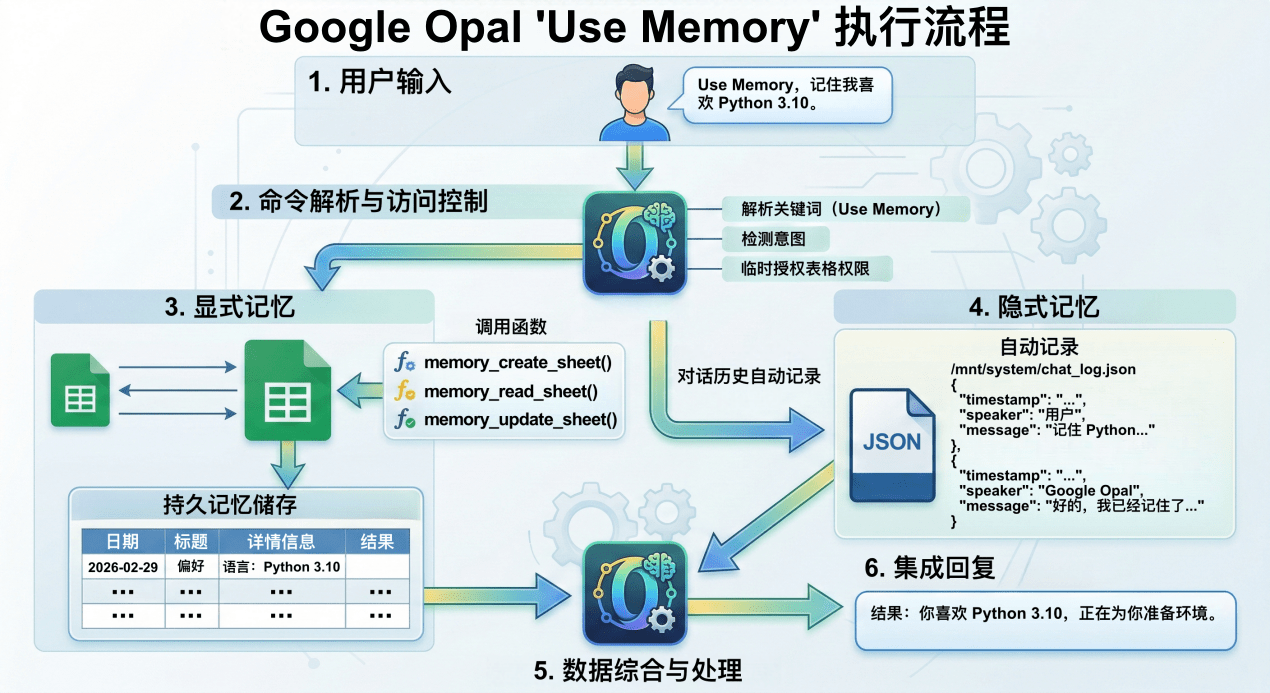
- 在处理的过程中,如果节点包含了 Use Memory 关键词,系统会先调用 memory_get_metadata 函数,查看是否有现成的表格。
- 如果找不到匹配的表格,就会执行 memory_create_sheet 函数创建一个包含“日期”、“数据”、“详情信息”的表格。
- 当节点处理完信息后,会调用 memory_update_sheet 将结果保存到表格里。
- 当下个节点执行的时候,会通过 memory_read_sheet 函数从表格中获取之前保存的全局数据进行分析理解。
适用场景
比较长比较复杂的流程
每一步生成后都保存结果,后续生成节点可以不断优化前面的版本
多轮信息整合
不同节点分别负责收集、分析、总结信息,再通过记忆整合全部信息。
注意:仅在必要的情况下使用 Use Memory 功能,滥用 Use Memory 功能会导致存储冗余。当表格中堆积了大量无用的中间过程数据时,模型在读取数据时可能会受到噪声干扰,反而降低了对核心指令的响应精度,最终导致生成的结果可能达不到预期的效果,或者容易出现幻觉。
对比效果
测试条件:在 input 中,输入的内容是 123.
经过前面 3 个节点的处理,最后一个生成节点只记住了上一个节点的结果,所以最后输出结果只记录到了内容 3。
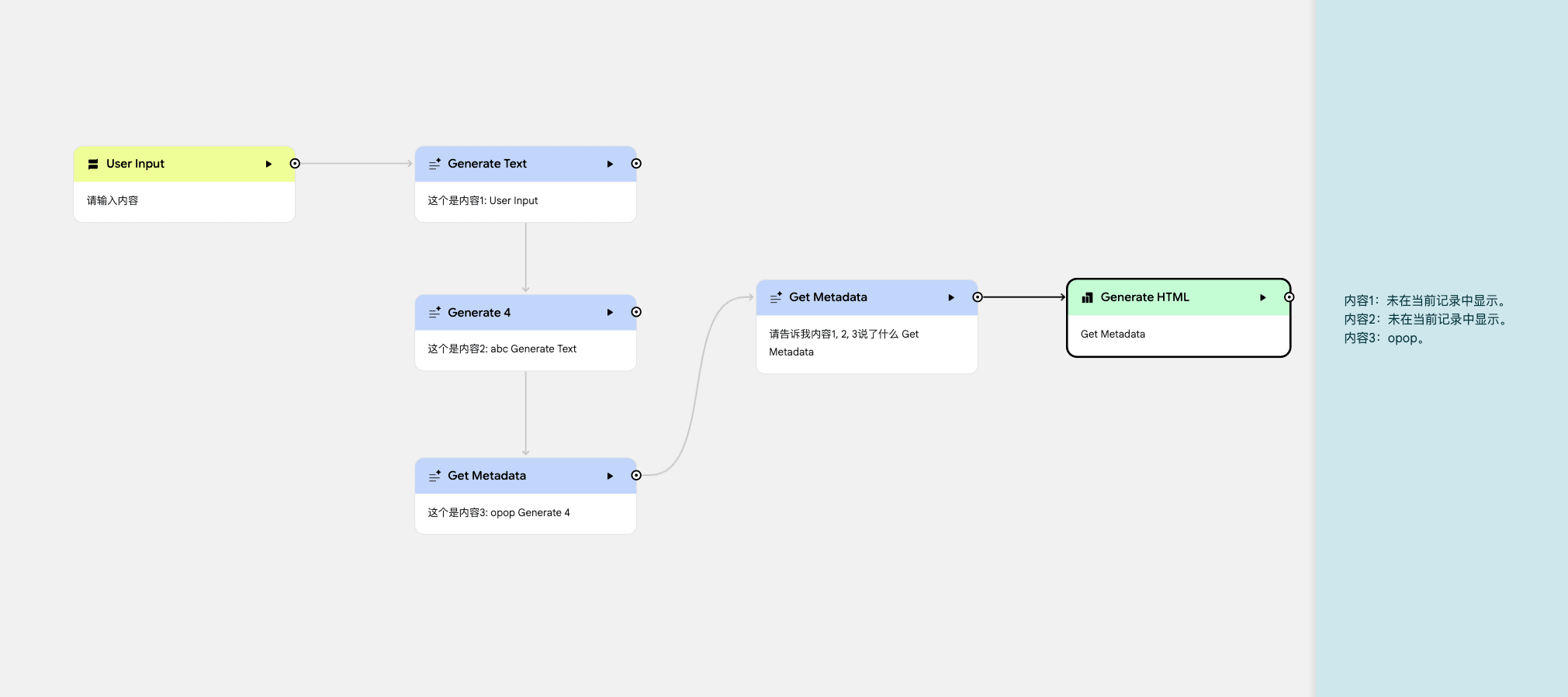
即使把前面每一个生成节点的结果都接入到最后一个生成节点,效果也是不如人意,只记住了最后一个连接的节点的结果。
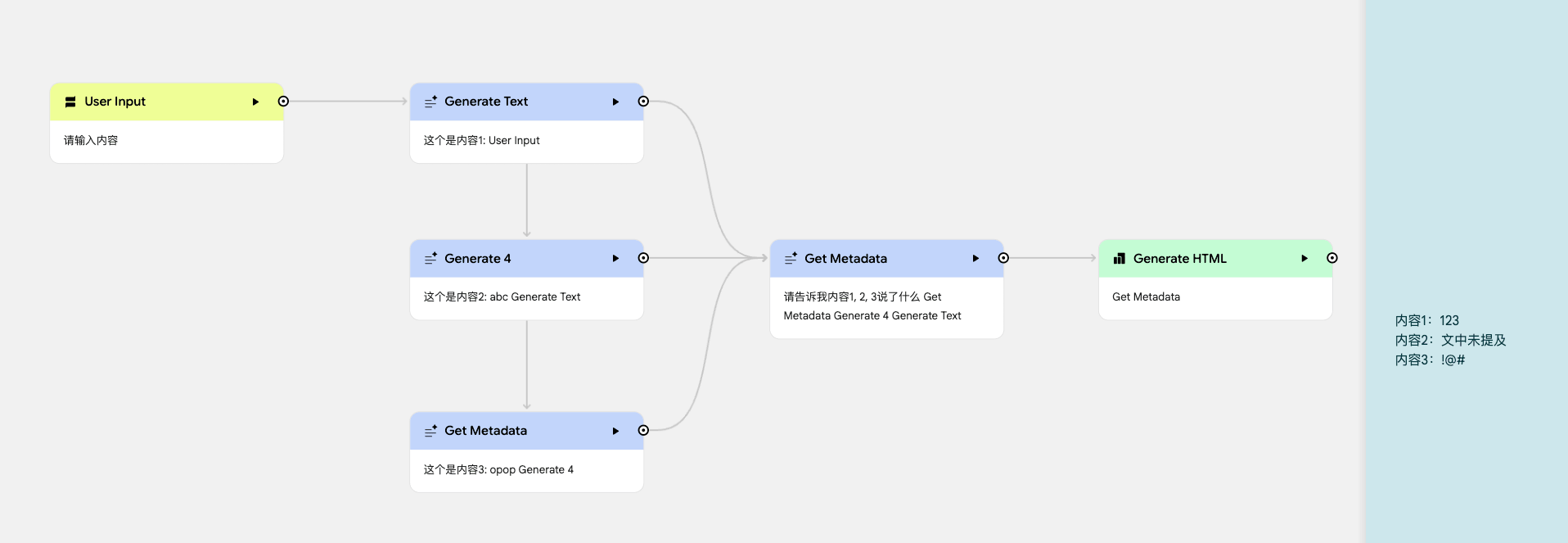
使用 Use Memory 功能后,最后一个生成节点就可以完整的记住全部的内容,正确的输出结果了。